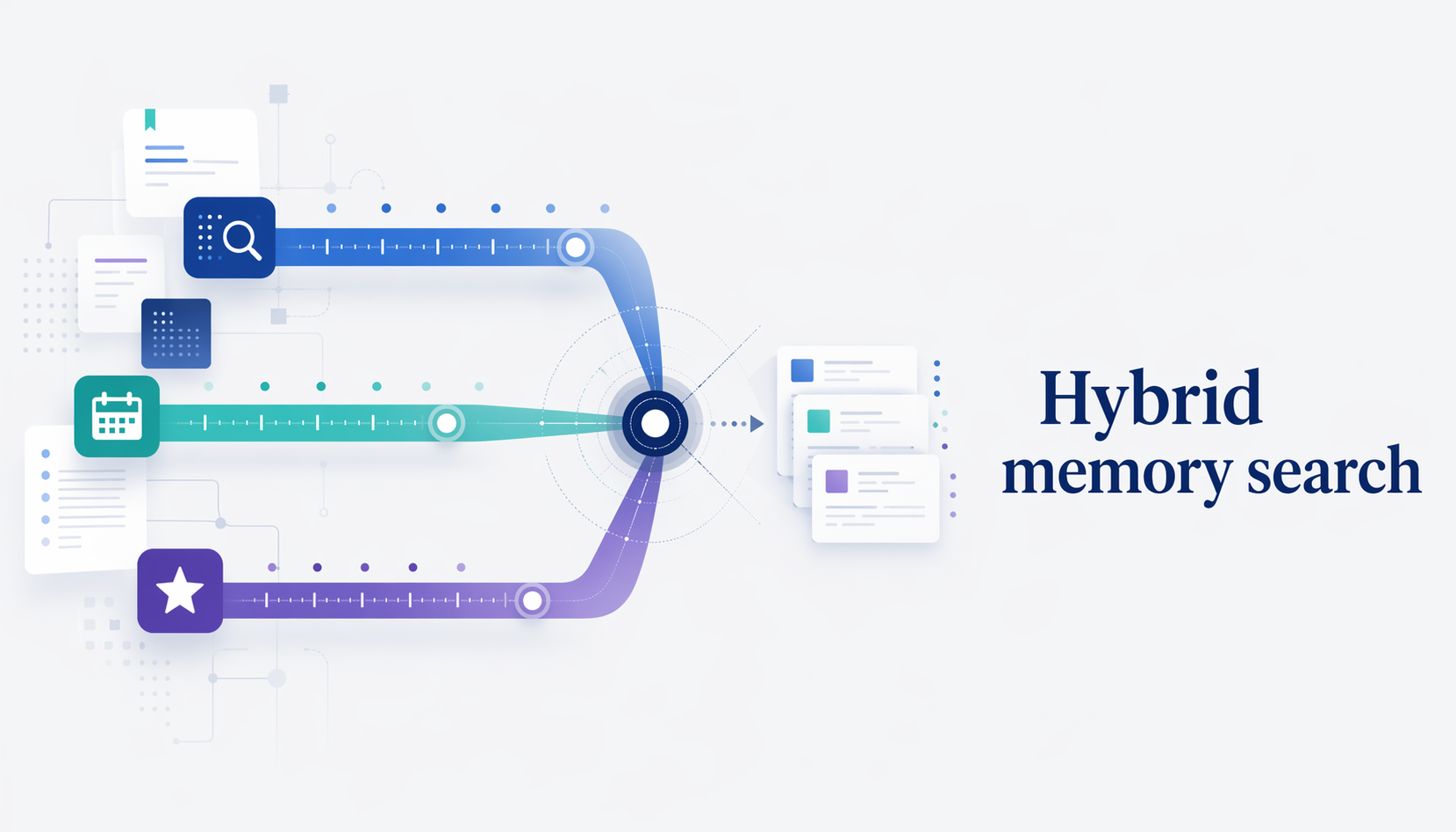
Hybrid memory search:把 journal 搜尋當成 ranking 問題
給 LLM agent 用的記憶系統寫了半年,最後發現自己打開次數最多的不是 MEMORY.md 或主題筆記,而是 memory/YYYY-MM-DD.md 這份逐日 journal。日常查的也多半是「上次搞 PostgreSQL 是什麼時候」「那個 config 的決定寫在哪天」這種問題。 問題是:搜尋它不太好用。 grep 噪音太多。半年的 journal 把任何常用詞炸出幾百個 hit。 embedding-only 搜尋對 journal 不適合。journal 裡面多半是兩三行的短 entry,embedding 模型給短句的向量區分度不夠;而且 journal 每天長,每次 incremental embed 都要算 hash、做 rate limit、管 cache,出錯就是一整天的記憶搜不到。 最關鍵的是,journal 是本質上有時間性的資料。我問「上次搞 PostgreSQL 是什麼時候」,語意相似度幫不上忙,時間才是主角。 所以我把 journal 搜尋重新當成一個 ranking 問題,用三個分數軸融合:keyword overlap × temporal recency × hall-type boost。Python 不到 130 行,沒有外部依賴。 這篇記錄設計過程、實測結果,還有一個在 bootstrap 測試時才發現的 case-sensitivity bug。 為什麼不直接用 embedding 先說清楚:embedding 不是沒用。我自己在 notes/ 的相關筆記推薦也還是用 embedding 跑 cron。問題是把它用在 journal 搜尋上有幾個具體的不匹配: ...




