看起來像「真的沒事件」
某天早上 8:55 看 daily report,Polymarket bot 連續第 3 天 0 信號:
=== Polymarket Bot 2026-04-26 08:55 CST ===
🔍 掃描: 2026-04-26 07:56 | 無信號
💰 餘額: $57.47 | 持倉 1 筆
📝 t2-20260423-111155.log
共同問題是三個信號都 (no summary),MM 沒提供可驗證的新聞依據...
📊 累計 6 筆交易 | 最後交易: 2026-03-29
第一感覺是政治冷淡期——4 月底國際新聞確實淡。Cron log 看下去:
[2026-04-26 00:35:22] Exit signals: 0
[2026-04-26 00:35:22] News: 0 signals
[2026-04-26 00:35:23] Correlation: 0 signals
[Sun Apr 26 00:35:23 CST 2026] No signals, skipping
... (連續 9 次都長這樣)
每 30 分鐘一次 cron、整天都「No signals, skipping」。看起來都正常運作、只是真的沒事件。
但手動跑 news_scanner.py 立刻回 5 個訊號:Iran 軍事行動 / Hormuz 解封 / al-Sharaa 會面 / Trump 訪中 5/15 等,confidence 0.65–0.78、delta 0.13–0.245。
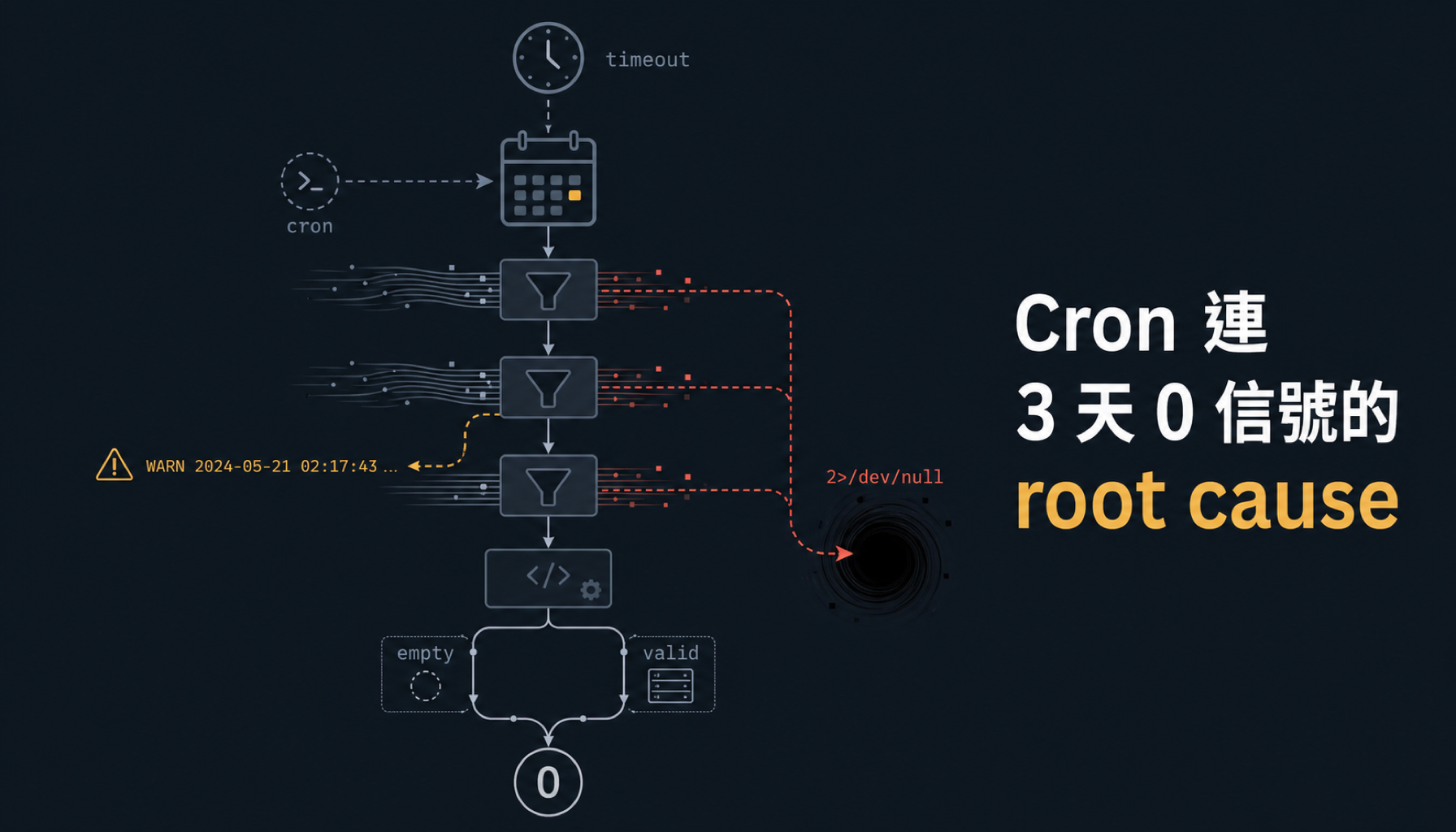
這代表訊號在、scanner 也正常——只是 cron 看不到它們。
三層 silent
scripts/collect.sh 第 93 行長這樣:
PYTHONPATH=~/projects/polymarket-bot timeout 50 python3 agents/news_scanner.py \
> /tmp/pm-news.json 2>/dev/null &
PID_NEWS=$!
# ... 後面 wait $PID_NEWS
NEWS_JSON=$(cat /tmp/pm-news.json 2>/dev/null || echo "[]")
log "News: $(echo "$NEWS_JSON" | python3 -c 'import json,sys;print(len(json.load(sys.stdin)))' 2>/dev/null || echo 0) signals"
這條指令把三件事疊加在一起:
| 層 | 行為 |
|---|---|
1. timeout 50 | 50 秒到自動 SIGTERM |
2. 2>/dev/null | stderr 全丟掉,包含 timeout 殺進程的訊息 |
3. parser || echo 0 | JSON 解析失敗時 fallback 為 0 |
同 prompt 連跑 3 次量 news_scanner.py 實際耗時(外層給 timeout 180 跑、確保不會誤殺):
| Run | command | 結束原因 | stdout bytes |
|---|---|---|---|
| 1 | timeout 180 python3 agents/news_scanner.py | exit 0 | 2865(5 signals) |
| 2 | 同上 | exit 0 | 3585(5 signals) |
| 3 | 同上(高峰時段) | exit 0 | 約 3 KB(5 signals) |
3 次分別跑 29s / 69s / 約 90s——MiniMax M2.7 是 thinking model,回應時間波動很大。
對照原 cron 設定 timeout 50:
| Run | command | 結束原因 | stdout bytes |
|---|---|---|---|
| 1 | timeout 50 python3 agents/news_scanner.py | SIGTERM at 50.0s | 0 |
50 秒對這個 model 是邊界值——快的時候穩過、慢的時候被殺。連續 3 天剛好都撞上慢的那邊。
被殺後 stdout 是 0 bytes,/tmp/pm-news.json 是空檔。下游 parser 走 || echo 0 退回零,cron log 寫「News: 0 signals」當作正常的「真的沒事件」分支跑下去。整條 pipeline rc=0、無錯誤訊息、log 看起來健康。
連續 3 天每 30 分鐘都這樣 silently fail。
修法(分兩批)
3 層 silent 對應 3 個修補點。第一批(前兩層)當天就修了恢復信號流;第二批(parser fallback)幾天後才補進去。
第一批:timeout + stderr 改向
# 1. timeout 50 → 150(4× 最快典型耗時、給 thinking model 抖動空間)
PYTHONPATH=... timeout 150 python3 agents/news_scanner.py \
> /tmp/pm-news.json 2>/tmp/pm-news.err &
# 2. stderr 從 /dev/null 改寫進專屬檔,留 SIGTERM / Python traceback / 上游連線錯誤等證據
# 3. 外層 cron-wrapper.sh 的 timeout 180 → 240
# 新內層 wait 上限 = max(news 150, correlator 120) = 150s
# + 前後 chain calls ~30s = 180s 用滿、留 60s 餘量
第一批 e2e 驗證:bash scripts/collect.sh 33 秒完成、回 5 個 news signals(Iran / Hormuz / al-Sharaa / Trump 訪中等 4 月底真實事件)。前一晚還在連續 0 信號的 bot 立刻恢復。
第二批:parser 區分「empty / invalid / valid」三分支
第一批修完隔幾天,回頭看才發現:就算上游壞掉,parser 還是會 silent 退回 0——因為原本長這樣:
NEWS_JSON=$(cat /tmp/pm-news.json 2>/dev/null || echo "[]")
log "News: $(echo "$NEWS_JSON" | python3 -c '...print(len(...))' 2>/dev/null || echo 0) signals"
|| echo 0 把「上游 timeout 死掉、檔案 0 bytes」跟「上游正常回 0 結果」壓成同一條路徑。第一批修補只是把 timeout 拉寬讓「上游死掉」機率變小,沒解決 silent 本身。
把它改成顯式 3 分支:
NEWS_BYTES=$(wc -c < /tmp/pm-news.json 2>/dev/null | tr -d ' ' || echo 0)
if [ "${NEWS_BYTES:-0}" -eq 0 ]; then
log "WARN: news_scanner upstream empty output (timeout/sigterm/no run); stderr in /tmp/pm-news.err"
NEWS_JSON="[]"
NEWS_COUNT=0
elif ! python3 -c 'import json,sys; json.load(open(sys.argv[1]))' /tmp/pm-news.json 2>/dev/null; then
log "WARN: news_scanner output not valid JSON (${NEWS_BYTES} bytes); stderr in /tmp/pm-news.err"
NEWS_JSON="[]"
NEWS_COUNT=0
else
NEWS_JSON=$(cat /tmp/pm-news.json)
NEWS_COUNT=$(echo "$NEWS_JSON" | python3 -c 'import json,sys;print(len(json.load(sys.stdin)))')
fi
log "News: ${NEWS_COUNT} signals"
實測 3 條 path 各觸發各的 WARN:
| 情境 | NEWS_BYTES | log 訊息 |
|---|---|---|
| Upstream 正常 0 結果 | [] 2 bytes | News: 0 signals(無 WARN,正常路徑) |
| Upstream timeout 殺掉 | 0 bytes | WARN: news_scanner upstream empty output ... + News: 0 signals |
| Upstream JSON 壞掉 | 9 bytes ([{"foo":) | WARN: news_scanner output not valid JSON (9 bytes) ... + News: 0 signals |
下游業務邏輯仍然把 NEWS_COUNT=0 視為「沒事件」沒差,但 cron log 多一行 WARN: ... 之後 grep 一搜就看到,silent fail 時間從「3 天才察覺」降到「下次看 log 就知道」。
不是孤例:silent fail 家族
修完之後跑了一下自己 LEARNINGS.md 內的 promotion-check,發現過去半年累積了 5 條主題高度相關但各自獨立的 entry:
| ID(日期) | claim 摘要 |
|---|---|
KG-20260413-006 | curl -sf 對 4xx/5xx 也算 fail,不適合當網路就緒探測——HTTP 拿到 401 也會 silent 回 1 |
BP-20260418-001 | Hook / job timeout 必須 > 內部 subprocess timeout + overhead——否則外層先殺、看起來像 pass 但內層其實沒跑完 |
CORRECTION-20260423-001 | 外部 API key 從沒設過 + try/except 吞 auth fail = 永久 silent degradation——Brave Search 我設過 key 但沒寫進 .env,code 跑了一個月,401 全部被吞 |
BP-20260423-003 | 外部 source 整合驗證三要素:size × Last-Modified × 首行內容——靜態 hub 頁假裝是動態 feed 已經跑了 27 天 |
KG-20260426-001 | 這次的:subprocess timeout 配 2>/dev/null 在 cron pipeline 是雙重靜默 |
5 條從 2026-04-13 到 04-26 跨 13 天,講的是同一件事的不同表面:自動化 pipeline 中「沒有錯誤訊息」≠「沒錯」。
如果合在一起當一個 meta-pattern 看,rc=5 / evidence 跨 13 天——遠比 5 條各自 rc=1 有說服力。但每次踩坑時都覺得「這跟之前那條像,但又有點不一樣」就開新 entry,造成現在這個碎片化現象。這個自我觀察本身又是另一個 lesson 了。
Cron pipeline 三條通則
從這 5 條合起來看,cron 自動化 code 寫起來該守的線:
1. 永遠不用 2>/dev/null 在 cron pipeline
/dev/null 是 silent fail 的最大幫兇。stderr 改寫進專屬 log:
# Bad
my-cmd args > out.json 2>/dev/null
# Good
my-cmd args > out.json 2>>"/tmp/$(basename "$0" .sh).err"
下次 silent fail 至少有 SIGTERM / Traceback / connection refused 線索可看。多花的成本:每次 cron run +1 KB 的 err log,週期 cron 大概一個月幾 MB,janitor 順手處理掉就好。
2. timeout 設 4× 典型耗時
不要設邊界值。如果某個 subprocess 平常 30 秒跑完、95th percentile 60 秒——timeout 不該設 50 秒、也不該設 60 秒,設 120 秒以上。
外層 wrapper 的 timeout 必須 ≥ 所有並行內層 timeout 的 max + 前後 chain call 時間 + 安全餘量。算一下:
collect.sh 內:
news_scanner timeout 150 (parallel)
market_corr timeout 120 (parallel)
→ wait 上限 = max(150, 120) = 150s
前面 chain calls (balance / positions / market resolver) ~30s
後面 summary JSON 組裝 ~3s
collect.sh 總時長 ≤ 150 + 30 + 3 = ~185s
外層 cron-wrapper.sh:
timeout 240 給 collect.sh ← 必須 > 185s
外層短於內層 sum 的話,外層先殺,內層工作半途中斷、檔案半寫狀態,下次 cron 又重來。
3. Parser fallback 前必須區分「空 input」vs「invalid input」
很多 parser 寫成這樣:
RESULT=$(echo "$JSON" | python3 -c 'import json,sys;print(len(json.load(sys.stdin)))' 2>/dev/null || echo 0)
|| echo 0 把「上游 timeout 死掉沒輸出」跟「上游正常回 0 個結果」混成同一條路徑。下游看到 RESULT=0 完全沒辦法區分:
| 情境 | input | 應該如何處理 |
|---|---|---|
| Upstream 正常 0 結果 | [] | 真的沒事件,正常路徑 |
| Upstream timeout 殺死 | `` (0 bytes) | 應該告警 |
| Upstream JSON 壞掉 | [{"foo | 應該告警 |
修法:分支處理:
if [ ! -s /tmp/pm-news.json ]; then
log "WARN: news_scanner upstream timeout or no output"
NEWS_COUNT=0
elif ! python3 -c 'import json,sys; json.load(sys.stdin)' < /tmp/pm-news.json 2>/dev/null; then
log "WARN: news_scanner output not valid JSON"
NEWS_COUNT=0
else
NEWS_COUNT=$(python3 -c 'import json,sys;print(len(json.load(sys.stdin)))' < /tmp/pm-news.json)
fi
多寫 5 行 bash,下次 silent fail 直接寫進 cron log,搜「WARN: news_scanner upstream timeout」立刻看到。
補充:「連續 N 次零信號」對你的場景是不是異常?
如果你的 cron 業務對 0 結果有歷史 baseline——例如 Polymarket bot 過去三個月平均 3-5 條/天、最久連續 0 也只 4 小時——那連續 3 天 0 就是離 baseline 太遠的離群值,要嘛 silent fail 要嘛上游全掛,兩種都該告警。
我不會說「0 信號連續多次一律是異常」這種一般化結論——對某些 cron(例如平日才有事件的工作流)連續 30 小時 0 才正常。重點是用你自己的歷史 baseline 設門檻,超過再 TG 告警,去人工 check upstream 健康。
這次踩到底是因為「3 天 0」被我當成「政治冷淡期」吃掉、沒對照 baseline。
收尾
silent failure 是 cron 系統最大的敵人——比 crash 還危險,因為它看起來「在跑」。
寫 cron 時值得每個 subprocess 都問自己:「如果它現在被 SIGTERM 殺、connection refused、disk full,外層 cron run 的 log 會看到什麼?」如果答案是「跟正常跑完一樣」,那你已經種了一個 silent fail trap。
這次的修補分兩批進去:第一批改 timeout 50→150 + stderr 從 /dev/null 改向專屬檔(解了 90% 機率不再撞 silent),第二批把 parser fallback 拆成 empty/invalid/valid 三分支(剩下 10% 也會明確 WARN 進 log)。實測上線後:
- 隔天的 cron 連續穩定回 5 個 news signals 跟手動跑一致
/tmp/pm-news.err累積了一些 SearXNG 連線抖動的 stderr(之前都被吞掉、不知道有過)
代價就是多寫 15 行 bash + 一個 stderr log——對 cron 健康來說很划算。