MK’s Lab 🧪
AI agent、espresso、和各種數位工具的實驗記錄

我在 Mac 上跑一個叫 cc-memory-project 的個人 agent 環境(從 OpenClaw workspace 演化來的),有自製的 hybrid memory search、knowledge graph、cron → flag → SessionStart hook pipeline。一直缺一塊:人不在電腦前的時候,沒辦法用手機驅動它。 這篇記錄怎麼用 Claude Code 原生的 channels 功能把 Telegram 接回來、做成開機常駐,計價路徑怎麼選,以及部署過程踩到的四個坑。順帶講同一段時間長出來的兩個搭配能力:記憶的混合搜尋,跟抓 X/Twitter 走遠端瀏覽器。 為什麼是現在接回來 之前想過用 tmux 加一層腳本去駭出一個遠端輸入管道,一直沒做。結果 Claude Code 自己補上了 --channels:原生支援把外部聊天介面(Telegram、Discord 等)接成 agent 的輸入輸出端。官方做掉了我本來要自己駭的東西,那就不用駭了。 另一個推力是計價。Anthropic 五月公告,六月中之後 claude -p、Agent SDK、GitHub Actions、以及經 ACP 認證的第三方 app,會從訂閱池移出去、改吃獨立的月度 credit。但互動式 TUI(terminal 或 IDE)明確不受影響、繼續吃訂閱。所以如果我能讓 Telegram bridge 走的是「互動 TUI」這條路,就不會被新政策抽走額度。 計價路徑:先確認走的是哪條 動手之前先做了一個關鍵驗證:claude --channels(互動模式,不加 -p)開出來的 session,它的 entrypoint 是什麼。 # 開一個 channels session(用一個假的 echo plugin 測) claude --channels plugin:fakechat@claude-plugins-official # 然後去翻這個 session 的 jsonl,抓 entrypoint ls -t ~/.claude/projects/<project>/*.jsonl | head -1 \ | xargs grep -o '"entrypoint":"[^"]*"' | head -1 結果是 entrypoint=cli,不是 sdk-cli。這就確認了:claude --channels 是互動 TUI 那條路,吃訂閱、不碰新的 credit pool。boot log 也看得到完整互動 TUI 起來、SessionStart hook 把記憶底圖載進去、訊息進來 agent 回應。 ...

為什麼把翻譯模型搬回本機 沉浸式翻譯(Immersive Translate)這類瀏覽器擴充預設走雲端 API,品質夠用,但有三個煩人的地方:網路 round-trip 是延遲主因、開「網頁語言檢測」每開一個 tab 就燒掉上千 token、敏感內容也得送出去。 翻譯是少數很適合丟給小模型的任務——它不需要通用推理,只要把一段文字準確地搬到另一個語言。一顆 1~2B 的翻譯專用模型在 Apple Silicon 上就跑得飛快,延遲、成本、隱私三件事一次解決。 我原本用的是 Tencent 的 Hunyuan-MT v2 1.8B(Hy-MT2-1.8B Q4_K_M,量化後 1.13GB),搭 llama.cpp 跑在一台 16GB 的 M4 上。在 M4 16GB 上實測約 72 tok/s,日常網頁、技術文件、字幕都夠。但用久了會撞到它的天花板。 1.8B 的弱點:跟 7B 同句對照就現形 同系列除了 1.8B 還有一顆 7B(Hy-MT2-7B,Q4_K_M 量化後磁碟上約 4.3 GiB;HuggingFace 頁面標 4.62 GB,差在 GiB 與 GB 的進位——這篇剛好在講單位)。把同一句餵給兩顆,差距很直接。以下都是 M4 16GB 上的實測輸出,目標語言只給泛稱「Traditional Chinese」: 來源句 1.8B Q4(~72 tok/s) 7B Q4(~19 tok/s) The Transformer is the backbone of… …現代大型语言模型的核心组件 …現代大型語言模型的核心 エヴァンゲリオン初号機にシンジが… 希真登上 EVA 初号机出击 真嗣駕駛初號機出擊 …about 1.1 gigabytes 模型文件大小约为 1.1 吉字节 模型檔案的大小約為 1.1 GB 差距落在三類。人名與單位是硬傷:日文人名「シンジ(真嗣)」1.8B 翻成不存在的「希真」、單位 gigabytes 翻成「吉字节」沒保留 GB;7B 兩個都對。這類要模型記得住約定俗成的譯名,1.8B 容量不夠,換 prompt 也救不回來。 ...

夏天到了,刷到 Morgan Eckroth 新發的 flash brew 影片,順手把 James Hoffmann 過去幾年三支冰咖啡影片跟查老師那支「一招解鎖超讚冰美式」湊到一起,發現手邊正好有六種不同做法可以並排看。 六種不是「哪個最好」的排名,是六種不同器材、不同思路的解法。你家有 V60 跟有 espresso 機,會走完全不同的路徑;你有蒸汽棒跟沒有,也是不同故事。這篇是對照筆記,不是教學文。 一個共同前提:冰咖啡跟熱咖啡不能用同一招 六種做法都在開頭做了類似鋪陳,但切入角度不同。 Morgan 從風味取向切:cold brew 不管放什麼豆都會收斂成「圓潤、巧克力、低酸」一個味道,但 flash brew 可以保留豆子本身的 brightness 和 acidity。如果你買了一支淺烘 Ethiopian,cold brew 等於浪費它。 Hoffmann 從化學切:cold brew 把豆子的 origin character 抹掉,hot brew 才能把 roaster 用心烘的東西萃出來。但冰水稀釋熱 brew 帶來新問題 — 萃取的 brewing water 變少,要好好萃出 flavor 變困難。 查老師 從感官神經科學切:低溫會讓舌頭對甜、酸、苦的感知都減弱(耶魯研究:舌頭碰冰甚至會誤感到鹹味)。所以冰咖啡要比熱咖啡萃得更濃,補償味覺鈍化。 三個人不約而同:冰咖啡不能照搬熱咖啡的做法。但理由都不一樣。 做法 A:Morgan 的 V60 + 冰塊(日式冰咖經典) 把總水量切成 60% 熱水 + 40% 冰塊。冰塊先放在 carafe 裡,熱水從上面 brew 下去直接淋融化。 項目 數值 粉量 20 g 總水量 300 g(1:15) 冰塊 120 g(40%,用過濾水做的冰) 熱水 180 g(60%) 水溫 205°F (≈96°C) 研磨 比平常 V60 再細 1–2 click Bloom 50 g / 40 秒 第二 pour 130 g(總到 180 g),螺旋手法 目標 drain time 約 3 分鐘 關鍵點:冰塊要用同水質的過濾水做。它會融進咖啡裡喝下去,不是只用來冰鎮容器。 ...

最近 Anthropic 官方放了一支 Building the future of agents with Claude 的對談,由 Alex Albert(Claude Relations)、Brad Abrams(Claude Developer Platform PM)、Katelyn Lesse(Engineering Lead)三人主持。12 分鐘左右,涵蓋 Claude Developer Platform 改名、agent 的定義、unhobble the model、Claude Code SDK 作為 general-purpose agentic harness、context pruning、agentic memory primitive、observability。 我在 Mac 上跑一個叫 cc-memory-project 的個人 agent 環境(從 OpenClaw workspace 演化),有自製的 hybrid memory search、knowledge graph、cron → flag → SessionStart hook pipeline。看完對談做了一些對映,挑兩個有具體 patch 落地的記錄一下。 五點對映 對談重點 我的個人 agent 現況 落地動作 Unhobble the model — scaffolding 在新模型上會變成 liability spec/ 三檔 + AGENTS.md / CLAUDE.md 約 800 行 砍 6 段過時 scaffolding(Group Chats / Heartbeats / 返工循環段移走 / MM 從主力改 fallback / 工具決策改 reference / OpenClaw sync 段濃縮)約 -1050 tokens SDK 是 general-purpose agentic harness 用 Claude Code 本身 + cron/hook/skill 自製 harness 不需動 Context pruning + tombstone memory-archive.py 把舊月份 section 直接刪掉 加 tombstone 留痕跡(第一個 patch) Agentic memory primitive hybrid search + graphify + hall taxonomy + always-on recall 不需動,方向對 Observability for long-running tasks SessionStart hook prompt-budget-telemetry 已寫 JSONL 升級為結構化 event(第二個 patch) Patch 1:Tombstone for archive_timeline scripts/memory-archive.py 的 archive_timeline 會把 MEMORY.md 裡 ### 2026-XX 這種舊月份 section 搬到 memory/timeline-archive.md。原本邏輯是直接刪除: ...

顆粒度焦慮(再一次) 我在 V60 Switch 上面卡住有一陣子了。 豆子在變、磨豆機刻度在動、水溫在試、開關閥的時機點在改。一杯偏酸往細調一點,下一杯又苦尾,往粗回半圈卻變寡淡。Switch 比一般 V60 多一個「閥開關」變因,本來想說多個工具應該更可控,結果反而更難 debug——因為任何一杯不對,我都不知道是顆粒度的問題、水溫的問題、還是我關閥的時機沒抓好。 於是我想說那就乖一點,找個現成的 recipe 跟著跑,跑十杯穩定下來再來動參數。問題是 recipe 我找了一週還沒找到「我要跟誰」。 原來大家在打架 打開 YouTube,James Hoffmann 教你 20g / 330g / 1:16.5、悶蒸關閥、單一水溫 95°C、2:30 開閥排水。Lance Hedrick 教你 15g / 250g、悶蒸還要用冷水(75°C)。 打開 bilibili 跟 PTT,全部都是粕谷哲(Tetsu Kasuya)的 4:6 神系:20g / 280g / 1:14、悶蒸開閥、前段 90°C 後段 70°C 雙溫。 中文圈最主流的 Kasuya 派和英文圈最主流的 Hoffmann 派,悶蒸時的閥位完全相反。一個是「先泡再濾」(關閥 immersion-first),一個是「先濾再泡」(開閥 percolation-first)。我在不同來源之間切換,等於每次都在動最關鍵那個變數。 難怪我的顆粒度怎麼調都不對——我每次測的時候連配方架構都不一樣,根本不是顆粒度的問題。 跟自己對齊的脈絡 意識到這件事之後,我把搜到的東西整理了一輪,包括: YouTube 上 Hoffmann、Hedrick、Kasuya、Emi Fukahori(2018 World Brewers Cup 冠軍)、Coffee Chronicler 的影片 bilibili 跟 PTT、Mobile01、小紅書的中文圈本地化版本 Home-Barista 論壇 t94108 / t85637 / t91685 三個主討論串(這個有點故事,後面講) 整理完之後我才看清楚,Switch 這個器具的真正分歧只在兩件事: ...
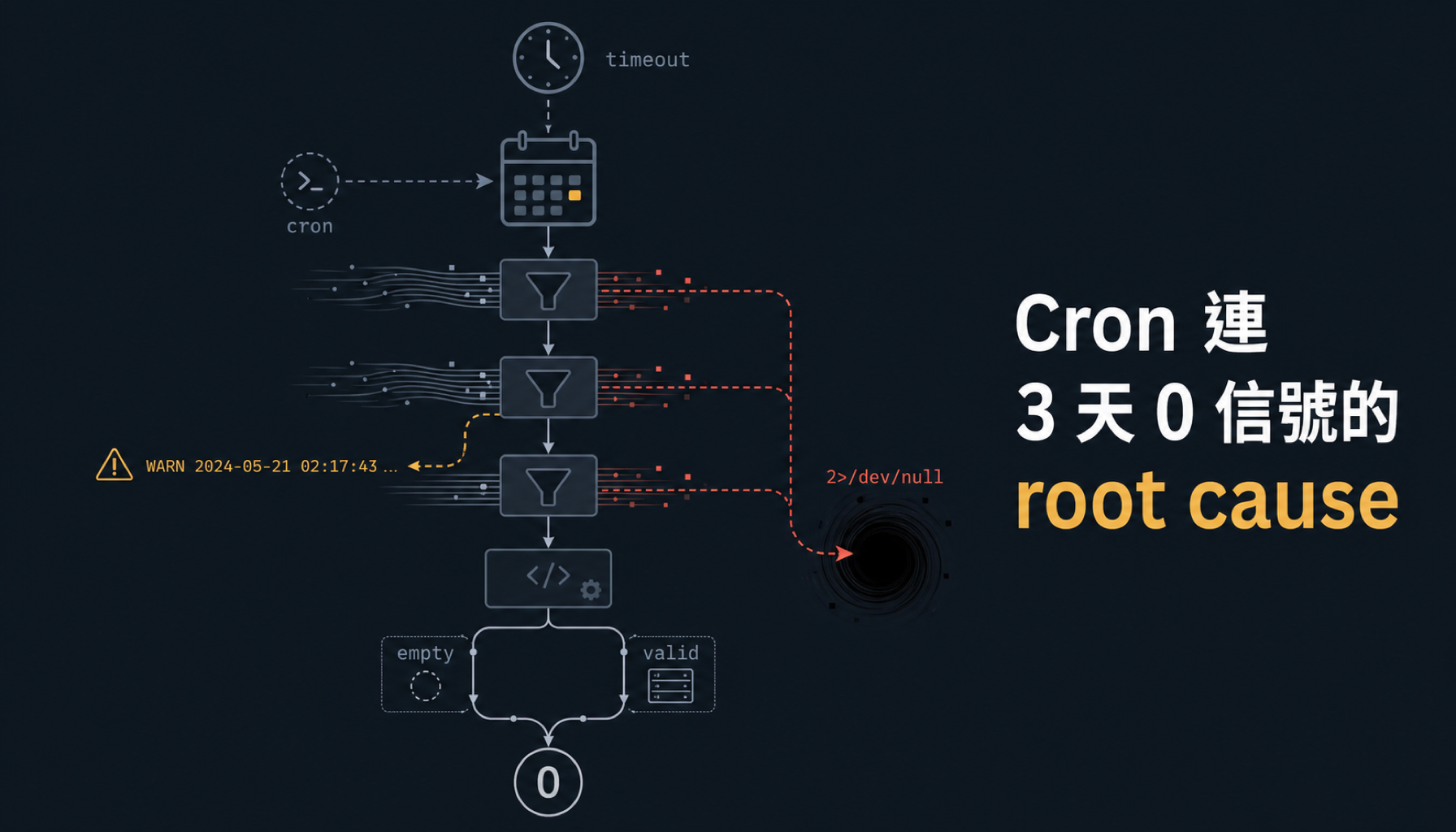
看起來像「真的沒事件」 某天早上 8:55 看 daily report,Polymarket bot 連續第 3 天 0 信號: === Polymarket Bot 2026-04-26 08:55 CST === 🔍 掃描: 2026-04-26 07:56 | 無信號 💰 餘額: $57.47 | 持倉 1 筆 📝 t2-20260423-111155.log 共同問題是三個信號都 (no summary),MM 沒提供可驗證的新聞依據... 📊 累計 6 筆交易 | 最後交易: 2026-03-29 第一感覺是政治冷淡期——4 月底國際新聞確實淡。Cron log 看下去: [2026-04-26 00:35:22] Exit signals: 0 [2026-04-26 00:35:22] News: 0 signals [2026-04-26 00:35:23] Correlation: 0 signals [Sun Apr 26 00:35:23 CST 2026] No signals, skipping ... (連續 9 次都長這樣) 每 30 分鐘一次 cron、整天都「No signals, skipping」。看起來都正常運作、只是真的沒事件。 ...

「Your pull request has been closed」 2026-04-26 早上打開 GitHub,看到一封 12 天前送出的 PR 來自 maintainer 的最新通知: Your pull request has been closed. State: CLOSED mergedAt: null 第一反應是嘆口氣——卡了 6 輪 bot review,最後還是被關了。準備重新開一個 issue 解釋為什麼這個方向是對的。 但點進去看留言才發現完全不是那回事。 12 天前發生了什麼 04-14 半夜我在用自己跑在 VPS 上的 AI agent,那個 agent 走 OpenClaw 串接 Discord。每個 Discord thread 可以綁一個 ACP(Agent Client Protocol)session 跟 Claude/Codex/Gemini 等 CLI agent 對話。 用到一半發現一個怪現象:在綁定 thread 內打 /acp close,原本應該關掉 ACP session,但卻被 ACP agent 當成「請求」吃掉,回了一段莫名其妙的對話。/status、/unfocus 也一樣。 trace 進 OpenClaw commands-acp.ts 發現 dispatch 路由跳過了 handleAcpCommand:在 ACP-bound 的 conversation 裡,所有 text 都被當 prompt 送給 ACP harness,連 /acp 開頭的管理指令都不例外。 ...

這個部落格有個存在很久的小債:17 篇文章裡,一張封面都沒有。每次打開文章列表都是一排光禿禿的灰底 placeholder,社群媒體分享預覽也只有標題文字。 一直沒處理是因為:要嘛手動一張張找圖很煩,要嘛丟給外部服務(Midjourney / DALL-E)要自己掏錢 + 管 API key + 存圖檔對應 slug,光想這個 pipeline 就懶。 直到昨天刷到一則推文:Codex CLI 0.122 把 gpt-image-2 預設打開了,不需要 API key,走你現有的 ChatGPT 帳號計費。配套還有一個叫 baoyu-skills 的 Claude Code skill 集合,專門餵 Codex 生各種規格的圖。 也就是說:整條 pipeline 已經在我手邊,只是我不知道。那今天就來補債。 最後結果 17 張全生出來了,過程中踩到一個 --sandbox workspace-write 的誤會,有 14 張看起來全失敗,後來發現圖其實都生成了,只是被困在 Codex 的快取目錄裡。這篇記錄流程 + 踩坑 + 救援。 驗證:Codex 真的能畫圖 先 live test。我的 Codex 版本剛好是 0.122.0。 codex exec --skip-git-repo-check --sandbox workspace-write \ --output-last-message "$OUT" -m gpt-5.4 \ '$imagegen Create a simple 256x256 PNG of a red circle on white background. Save as /tmp/test.png. Final message: only the file path.' \ < /dev/null 跑完 ls /tmp/test.png 就有了。32 KB PNG、256×256 8-bit RGB、花了 ~30k tokens。 ...

OpenAI 在 4 月 15 日更新了 Agents SDK,加入了 sandbox 隔離、Harness/compute 分離、Manifest 工作區描述、Capabilities 分層。看完技術文件後我的第一反應是「這跟我們在做的事情不一樣」,第二反應是「但裡面有幾個結構性概念可以偷」。 這篇記錄我們從中借了什麼、怎麼落地到 openclaw-workspace-template v3.0.0,以及為什麼大部分東西我們選擇不抄。 兩個系統的定位差異 先把前提講清楚:OpenAI Agents SDK 跟我們的 workspace template 解決的是完全不同的問題。 OpenAI Agents SDK 我們的 workspace template 目標使用者 企業,多租戶 SaaS 個人,單使用者 執行環境 雲端 sandbox(Modal / E2B / Cloudflare / Vercel) 本機 Mac / Linux,直接 filesystem access 權限模型 Tool calls 在 unprivileged container 裡跑,隔離網路和 secret 跟使用者同權限,能碰 git / cron / Telegram / Obsidian State serialize_session_state() / resume(),snapshot 整個 workspace 檔案系統就是 state,git 就是 snapshot Memory 內建 Memory() capability,session close 自動 summarize → consolidate 自建 MemPalace:hall-tagged journal + 主題筆記 + weekly reflection + knowledge graph OpenAI 在解的是「怎麼讓 agent 安全可靠地跑在生產環境」。我們在解的是「怎麼讓一個人的知識和自動化系統持續累積和整合」。拿來直接比就像比 AWS Lambda 跟家裡的 crontab。 ...
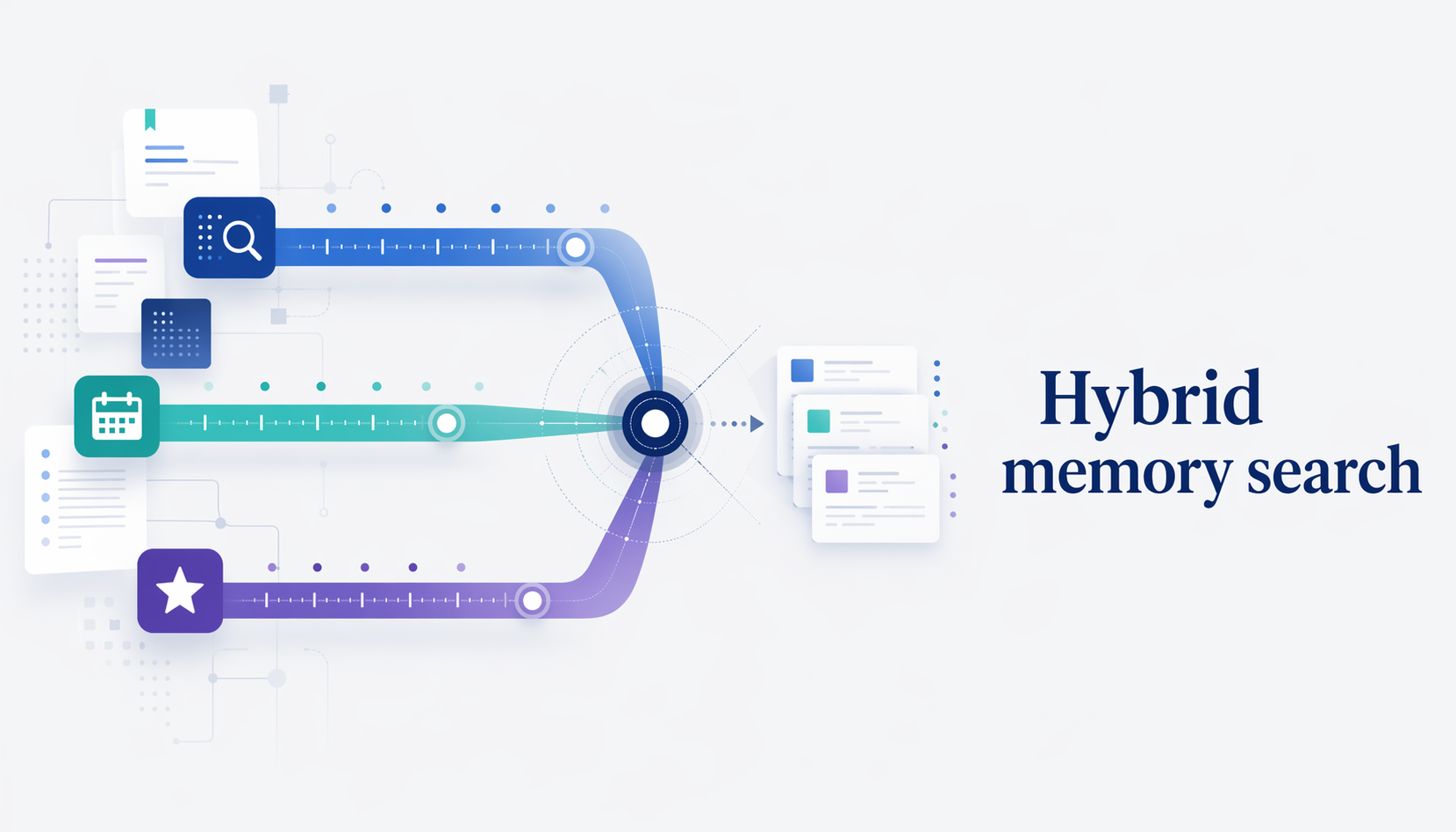
給 LLM agent 用的記憶系統寫了半年,最後發現自己打開次數最多的不是 MEMORY.md 或主題筆記,而是 memory/YYYY-MM-DD.md 這份逐日 journal。日常查的也多半是「上次搞 PostgreSQL 是什麼時候」「那個 config 的決定寫在哪天」這種問題。 問題是:搜尋它不太好用。 grep 噪音太多。半年的 journal 把任何常用詞炸出幾百個 hit。 embedding-only 搜尋對 journal 不適合。journal 裡面多半是兩三行的短 entry,embedding 模型給短句的向量區分度不夠;而且 journal 每天長,每次 incremental embed 都要算 hash、做 rate limit、管 cache,出錯就是一整天的記憶搜不到。 最關鍵的是,journal 是本質上有時間性的資料。我問「上次搞 PostgreSQL 是什麼時候」,語意相似度幫不上忙,時間才是主角。 所以我把 journal 搜尋重新當成一個 ranking 問題,用三個分數軸融合:keyword overlap × temporal recency × hall-type boost。Python 不到 130 行,沒有外部依賴。 這篇記錄設計過程、實測結果,還有一個在 bootstrap 測試時才發現的 case-sensitivity bug。 為什麼不直接用 embedding 先說清楚:embedding 不是沒用。我自己在 notes/ 的相關筆記推薦也還是用 embedding 跑 cron。問題是把它用在 journal 搜尋上有幾個具體的不匹配: ...